
El patrón Saga fue propuesto por Hector Garcia-Molina y Kenneth Salem en 1987. Puedes descargarte el paper aquí: SAGAS.
Basada en arquitecturas guiadas por eventos (Event Driven Architecture), las sagas nos garantizarán la consistencia de datos en las transacciones de negocio que involucren varias transacciones locales entre varios servicios o participantes en un determinado sistema distribuido.
Principalmente gestiona una secuencia de transacciones locales que completarán dicha transacción de negocio: cada transacción local de cada servicio se ejecutará basándose en el resultado de otros participantes o servicios mediante la comunicación de eventos de dominio.
Cada servicio deberá ser responsable de realizar su posible transacción de compensación (rollback) de una transacción local ya realizada correctamente en el caso de algún error reaccionando a los llamados eventos de compensación.
Existen dos tipos de gestión de sagas: basada en orquestación o coreografía.
Choreography
Los participantes reaccionan de forma autónoma. Cada servicio participa en la transacción distribuida de forma individual. Siendo responsable de gestionar su propia transacción local según la operación resultante de otro participante: continuar la saga o ejecutar la transacción de compensación (deshaciendo cambios ya realizados) desencadenando los eventos de compensación. Notificando si la transacción ha sido realizada correctamente o no, publicando el evento correspondiente.
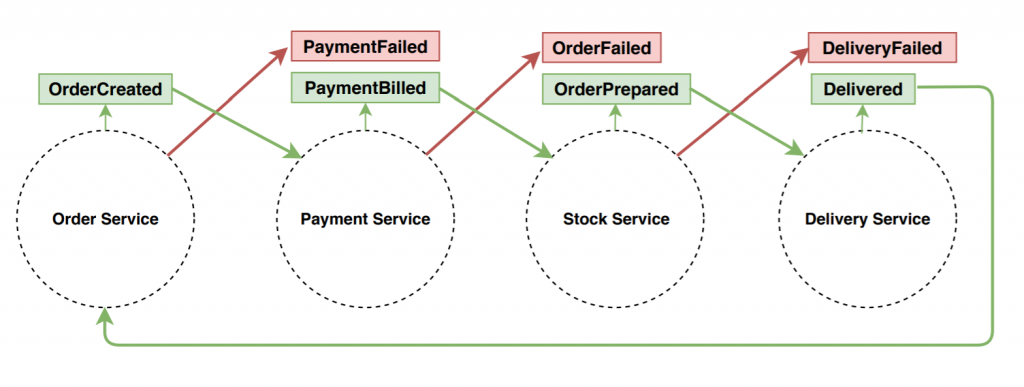
No existe un single point of failure y los servicios se encuentran totalmente desacoplados. Aunque (dependiendo del número de participantes o servicios que colaboren para garantizar la ejecución completa de la transacción distribuida) puede ocasionar un aumento en la complejidad dificultando las tareas de testing, debug y monitoring.
Orchestration
Los participantes son gestionados desde un único punto: el orquestador de la saga. Mediante una primera operación orquesta las llamadas secuenciales al conjunto de participantes para llevar a cabo la transacción de negocio distribuida.
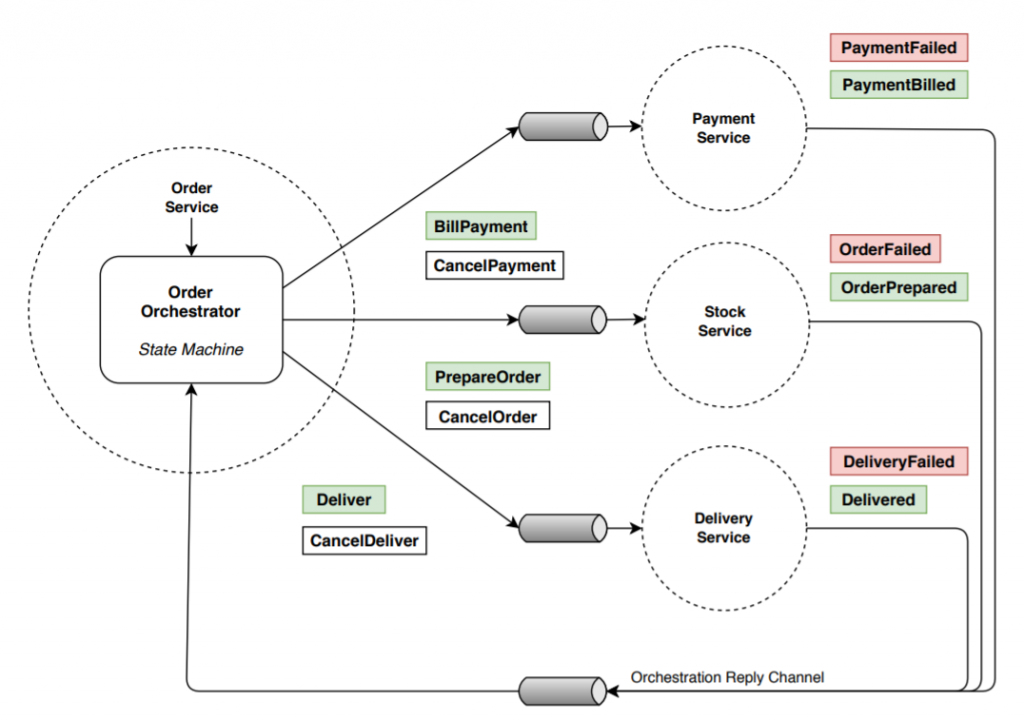
Si el orquestador detecta un error en alguna respuesta en la ejecución de algún participante ejecutará las acciones correspondientes de compensación en cada uno de los participantes ya ejecutados hasta el momento.
Las ejecuciones de los participantes se realizan asíncronamente siguiendo el orden necesario si se requiere. Pueden existir varias posibilidades de implementación dependiendo del stack tecnológico, aunque recomendable usar los patrones Remote Procedure Call (RPC) request/async response o request/replay en las comunicaciones con los participantes.
La ventaja principal es la visibilidad que aporta tener todo el workflow centralizado en el orquestador resultando más sencillas las operaciones de testing, debug y monitoring. Aunque disponemos de un único componente creando una dependencia entre los participantes.
Entonces, si realmente y lo verdaderamente importante en nuestro sistema son los eventos de dominio para mantener la consistencia de los datos, disponiendo además de diferentes estrategias y prácticas que solventan diferentes problemas en el momento que guardamos dichos estados (escritura) y otras cuando necesitamos consultarlos (lectura). La pregunta sería: ¿Porque no trabajamos únicamente con eventos?. Acercándonos así a Event Sourcing y CQRS.
Bajo mi punto de vista, la solución ante un problema dado en una situación y contexto concretos se encuentra en el equilibrio entre los costes y beneficios de cada decisión que tomemos en cada momento. Y las decisiones (si dispones de posibilidad de colaborar o influir en ellas, claro) mejor tomarlas en base a los datos que dispongas y conocimientos/experiencia del equipo. Y recuerda incluir como coste la complejidad que añadas.
Hasta aquí, de momento, los principales patrones que nos permitirán garantizar una consistencia de los datos. Lógicamente estas prácticas tendrán un coste de desarrollo, aunque ya hemos visto que este tipo de prácticas no son nuevas, no hará falta reinventar la rueda: tenemos disponible una gran cantidad de herramientas open source que nos facilitarán implementarlos (incluyendo servicios cloud como las Durable Orchestrations de Azure) basándonos así en patrones y guías comunes siendo más sencillo explicarlos y manteniendo siempre un orden y coherencia en nuestras prácticas.
Feedback is always welcome 🙂
Lecturas y charlas recomendadas:
- https://microservices.io/patterns/data/saga.html
- https://medium.com/@ijayakantha/microservices-the-saga-pattern-for-distributed-transactions-c489d0ac0247
- https://jimmybogard.com/life-beyond-distributed-transactions-sagas/