
Basamos (o deberíamos) las decisiones en base a los datos que almacenamos en la interacción de los usuarios sobre nuestro producto. Guardamos toda la información necesaria para dar respuestas y elaborar predicciones en base a históricos de datos. Adaptándonos y anticipándonos así a las necesidades de nuestros usuarios.

¿Te has preguntado si dichos datos son consistentes?
En este post trataremos la consistencia: en qué consiste y cómo ha evolucionado a lo largo de las diferentes arquitecturas, influencias y tecnologías.
Interpretamos que nuestros datos son consistentes si:
- Los datos se relacionan correctamente sin generar incongruencias. Existiendo una integridad referencial.
- Se mantienen estados válidos y concretos (la cantidad de unidades de un producto para un pedido coincide con el registro de salida de stock).
- Están disponibles para la lectura una vez se completada la transacción (acción u operación sobre la base de datos).
Los sistemas de gestión de bases de datos relacionales o SGBDR (SQL Server, Oracle, MariaDB, MySQL, etc.) nos garantizan la consistencia de los datos almacenados mediante ACID en sus transacciones:
- Atomicy: La transacción se ejecuta completamente, o no se ejecuta.
- Consistency: Sólo ejecutará la transacción si respeta las directrices de integridad referencial y reglas definidas, manteniendo en todo momento estados válidos y exactos.
- Isolated: Una transacción no puede afectar a otra garantizando que el estado final de ejecuciones concurrentes será el mismo que ejecutadas de forma secuencial mediante un control de concurrencia.
- Durability: Garantiza la persistencia de los datos una vez se haya ejecutada la transacción, aunque el sistema falle.
La principal e inicial arquitectura de alto nivel más común, extendida y que todos conocemos:
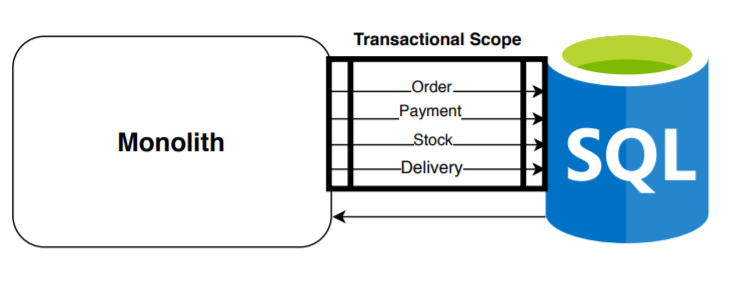
Disponemos de un componente principal que gestiona las transacciones realizadas a una única base de datos por cada caso de uso de la aplicación. Como veis en este ejemplo, ejecutamos una transacción (incluyendo en ella todas las operaciones necesarias para completar correctamente un nuevo pedido). Efectivamente, la base de datos relacional nos garantiza ACID ofreciéndonos consistencia en la creación de la totalidad del pedido, pero unos muy pobres resultados a nivel de eficiencia, escalabilidad y disponibilidad manejando grandes cantidades de datos.
En 1998, Carlos Strozzi introduce el concepto de NoSQL para su base de datos relacional de código abierto, ya que no utiliza SQL como interfaz de consulta. Eric Evans y Johan Oskarsson (last.fm) reintroducen el concepto NoSQL/NoREL refiriéndose a base de datos no relacionales (denormalización o desestructuración de los datos dando una mejor eficiencia).
Compañías como Twitter, Facebook, Amazon y Google lideran la adopción de las bases de datos no relacionales dada la necesidad de un procesado más eficiente de grandes volúmenes de información en un clúster distribuido de datos, permitiendo así un escalado horizontal. El concepto Big Data es oficial en 2005.
Empezamos a evolucionar las arquitecturas. Unos de los siguientes pasos más comunes fue el siguiente:
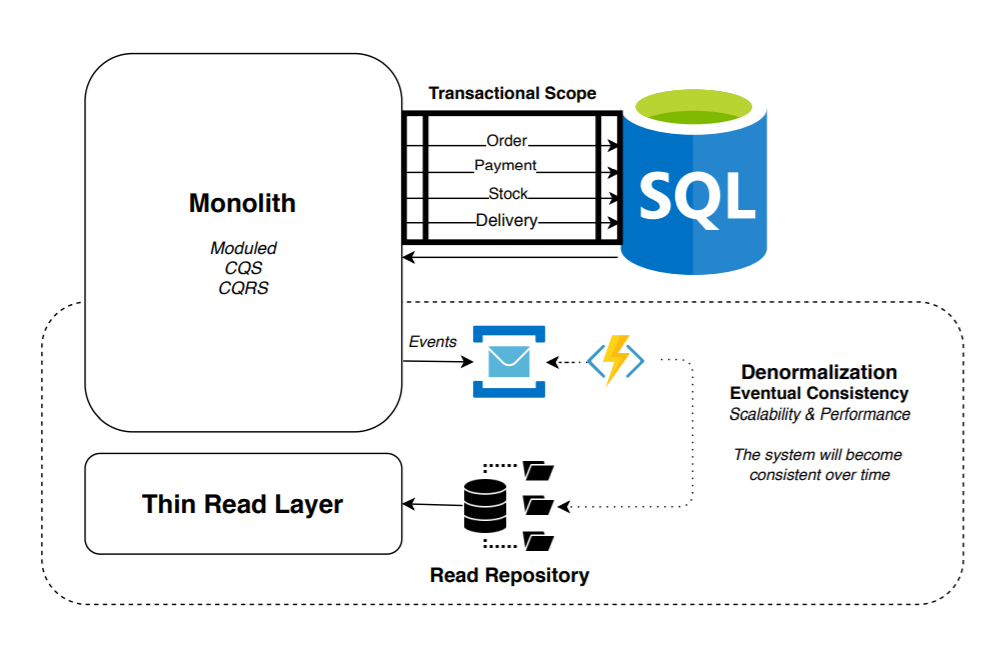
Se empiezan a integrar nuevas bases de datos NoSQL (Apache Solr, ElasticSearch, Redis, etc.) incrementando la velocidad de consulta de forma exponencial. Sincronizamos y transformamos los datos (proyectándolos y denormalizándolos) desde la base de datos relacional de escritura, hacia la base de datos no relacional de lectura mediante eventos de forma incremental (una vez suceden los cambios) o incluso mediante estrategias de control de cambios en la base de datos relacional.
Allá por el 2011 contaba mi experiencia con la implantación de Apache Solr: https://josecuellar.net/iniciacion-e-implementacion-de-apache-solr/
En este escenario se empiezan a dividir responsabilidades modularizando el monolito y empezado a separar los modelos de lectura y escritura. Patrones como CQS o CQRS empiezan a ser relevantes.
La consistencia de los datos entre ambas bases de datos se realiza de forma eventual (existe un delay en la recuperación de los datos): aunque manteniendo siempre un origen de datos (source of truth) fiable que garantiza ACID en sus transacciones de escritura (podíamos realizar en cualquier momento puntual una reparación de ciertos datos incongruentes que pudieran existir en el repositorio de lectura).
En este contexto y teniendo una solución equilibrada, empezamos a ser conscientes de la complejidad y acoplamiento adyacente que ocasiona disponer de un único componente (monolito) generando una gran cantidad de deficiencias en la calidad del código, modularidad, mantenibilidad y escalabilidad de la infraestructura.
En 2003, Eric Evans publica Domain-Driven Design: Tackling Complexity in the Heart of Software, aportando una visión estratégica de división del dominio mediante subdominios y bounded contexts. Así como técnicas de comunicación entre los bounded contexts según sus tipos de colaboración: context mappings.
Os dejo por aquí una serie de posts que escribí en la lectura de Implementing Domain Driven Design de Vaughn Vernon: https://josecuellar.net/domain-driven-design-episodio-i-empezando/
Reconocidas las ventajas y sufriendo los inconvenientes, empezamos a dar pasos a los siguientes tipos de arquitecturas con objetivo de dividir el monolito, creando bases de datos no relacionales de lectura por servicio, dividiendo las responsabilidades y adaptando los procesos de sincronización desde la base de datos transaccional.
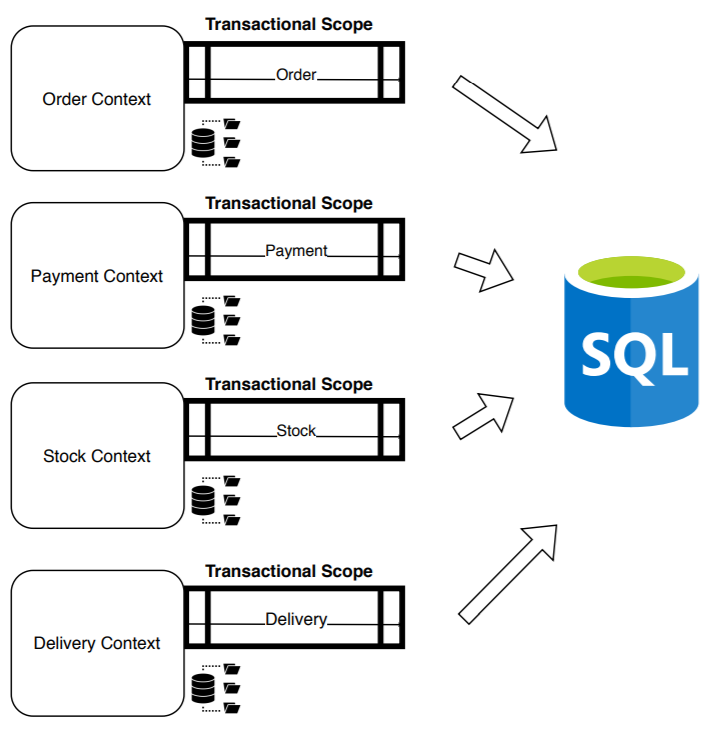
Con objetivo de desacoplar totalmente los contextos y evitar dependencias, necesitábamos dividir la base de datos: una base de datos transaccional por contexto:
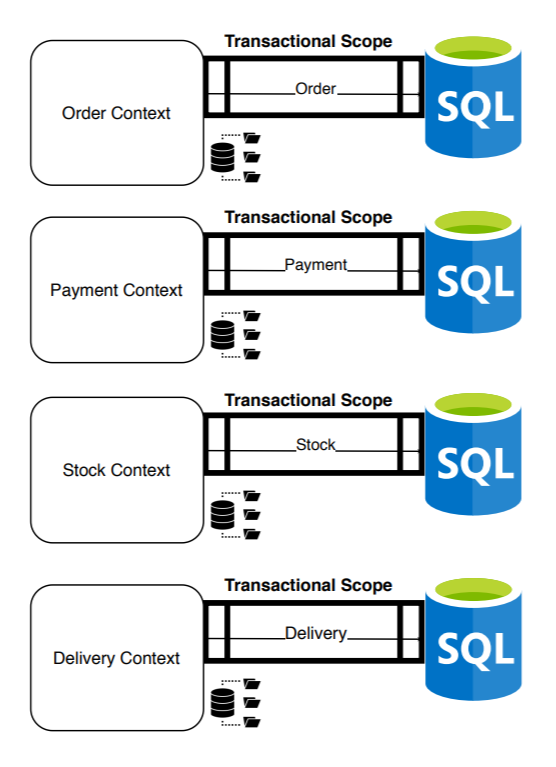
En este momento, disponemos de un sistema distribuido aumentando la flexibilidad, escalabilidad y disponibilidad. Aunque, hemos dividido el ámbito transaccional en la creación del pedido. Ahora, sólo garantizamos ACID en cada una de las transacciones individuales y no en la creación total del pedido: hemos resuelto infinidad de problemas pagando con la moneda de la consistencia. A partir de este momento, crear un pedido se convertirá en una transacción distribuida.
Los números y los datos empiezan a ser incongruentes: ¿Cómo puede ser que haya menos stock del que nos reflejan los reports? ¿Cómo es posible que existe un pago y no el abono si el pedido fue cancelado?, ¿Cómo podemos tener un pedido enviado sin salida del stock asociado? etc.
Recordemos el Teorema CAP (presentada por Eric Brewer en el año 2000) en el que explica que ante un sistema distribuido es imposible garantizar simultáneamente más de dos de las siguientes características: Consistency, Availability (recibe una respuesta no errónea pero sin garantías de que se recuperen datos consistentes) y Partition Tolerance (el sistema sigue funcionando incluso si alguno de sus nodos cae).
Eric Brewer concreta las características de los sistema distribuidos (basado en su teorema y excluyendo consistencia) a BASE (Basically Available, Soft state and Eventual consistency).
Por aquel momento, siguiendo la dinámica decantándonos por Partition Tolerance & Availability y descuidando la consistencia de los datos y otros factores (complejidad esencial vs complejidad accidental), seguimos aumentando nuestro sistema distribuido.
Sam Newman publica Building Microservices en 2014 convirtiéndose en un libro de referencia en la comunidad. Impulsando la dinámica de división y evolucionando nuestras arquitecturas hacia los microservicios:
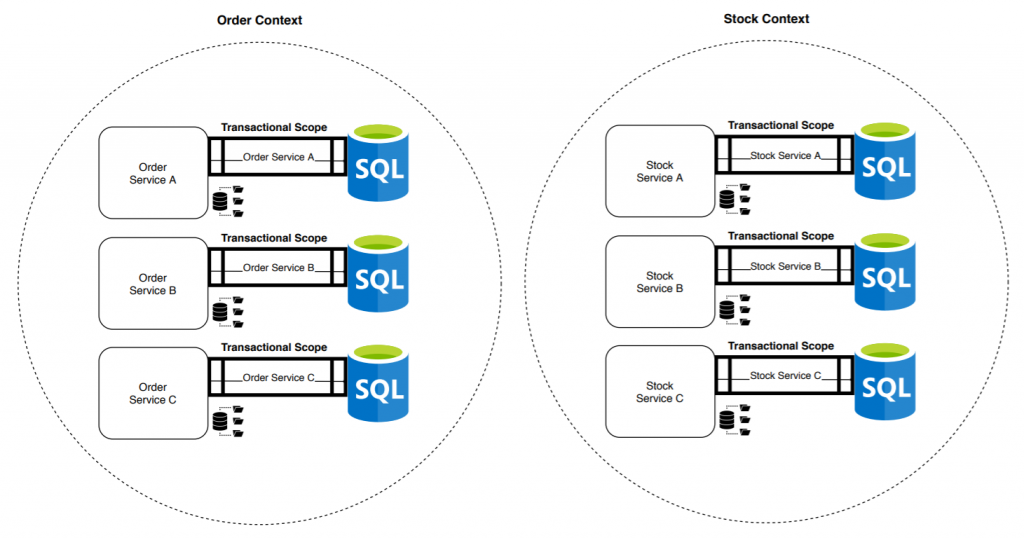
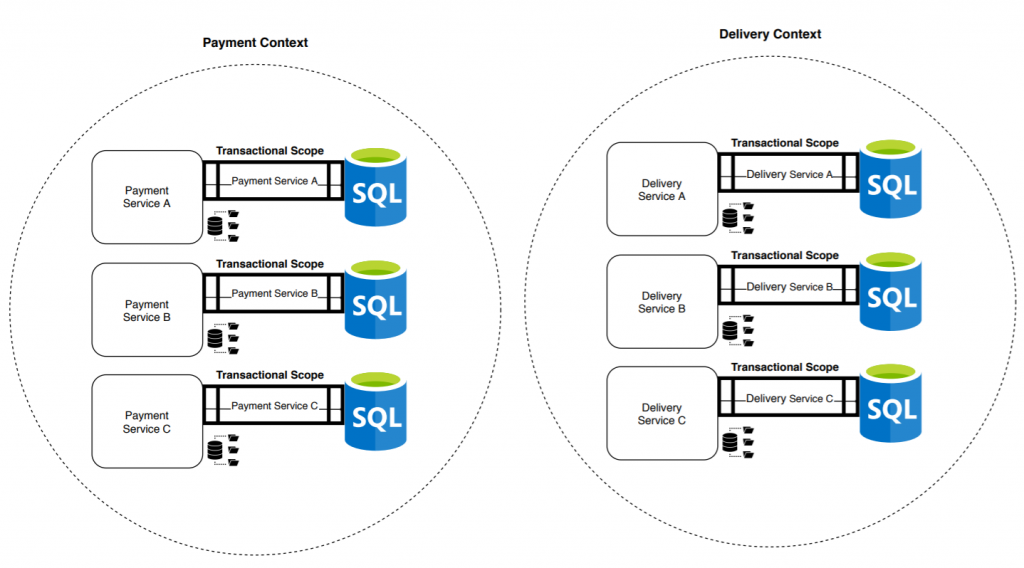
El bounded context se convierte en una agrupación cohesionada de microservicios. Ahora ya no tenemos una única transacción que garantice ACID, ni cuatro, sino doce: una por microservicio. El riesgo de inconsistencias de datos aumenta, así como la exigencia de conocimientos necesarios para enfrentarse a los problemas que genera este tipo de sistemas.
Mi intención principal en este post fue plantear y resumir el problema actual en la consistencia de los datos a lo largo del tiempo. Ya que parece que no prestamos la suficiente atención al problema y descuidamos prácticas que nos ayuden, como mínimo, a mitigarlo. Al fin y al cabo, la tecnología está al servicio del producto y la mejora del producto (entre otros aspectos), de los datos que genera.
Es cierto que no he detallado las grandes ventajas que ha supuesto dividir responsabilidades (lo dejo para otro post), que son muchas y muy variadas. Y dichas ventajas son las que siempre declinaron la balanza de nuestras decisiones hasta tener los sistemas distribuidos que tenemos habitualmente hoy en día. Aunque de vez en cuando, hay que intentar equilibrarla. O como mínimo, ser conscientes de lo que hemos dejado en el camino mediante pensamiento crítico.
En los próximos posts compartiré diferentes patrones que nos ayudarán a gestionar correctamente las transacciones distribuidas generando así un sistema más consistente sin sacrificar Availability y Partition Tolerance (Outbox Pattern y Sagas) y veremos otras posibilidades evitando trabajar con dos repositorios simultáneamente.